Add free private AI chat to your HomeLab with Ollama and Open WebUI
Deploy local AI Chat that is actually good, fast, and comparable to paid using metal you already own, no subscription required. We'll use Open WebUI as our ChatGPT like interface and Ollama as our local model runner. We'll integrate with premium online cloud models too!


That is actually good, fast, and uses the hardware you already have; no subscription required. It's not only comparable to ChatGPT, Claude, and Perplexity, but you can use those services as well, along with the latest local open-source models from Meta, Microsoft, Google, and others. If you are like me, you might have one or two Apple M-series Macs and maybe a gaming PC or laptop with an RTX GPU. You can use all of that hardware, that is otherwise used for work, web browsing, and games, to serve up local AI queries that can search the web, analyze images, and many more tasks you can enable or even develop yourself. These chats will be run locally, are stored locally, and never leave your home network...unless you want it to. We'll use the very cool and rapidly improving project Open WebUI as our ChatGPT-like interface and Ollama as our model runner and local API to respond to local chat queries. I've been using and fine-tuning my setup for a couple of weeks now and have been having a lot of fun. I think you will, too, so let's get into it!
We'll cover
- Setting up Ollama 🦙 on Mac and Windows as a service that is accessible on your local network.
- Setting up Open WebUI in Docker 🙂 and Kubernetes via a customized Helm chart 🤓. Choose what works best for you.
- Fully configuring Open Web UI to run local models like llama3.3, deepseek-r1, phi4, and gemma2 across multiple machines and integrating with OpenAI, Claude, Gemini, and Perplexity for a no-compromise local chat experience...for the whole family 🏠
- Finally, can this replace my AI subscriptions? I think it could, with some considerations 💪.
Ollama as a Service
Ollama is an awesome tool that I've been using for quite a while now, all by itself. With Ollama, you can pull down a model that is cable of running on your computer, and start chatting directly from your favorite terminal. Ollama will load the model and recognize your computer and architecture, automatically leveraging GPU Offloading via Apple Metal or Nvidia RTX to optimize performance. It's this functionality, along with their built-in API and your metal, that will power our local chat application.
We'll have to enable Ollama to do two things it doesn't do by default.
- Run all the time in the background
- Allow connections to its API from other machines on the local network by setting two environment variables OLLAMA_ORIGINS="*" and OLLAMA_HOST="0.0.0.0"
Configuring Mac M4 Mac mini
brew install ollama
nano ~/Library/LaunchAgents/com.user.ollama.plist
Configuring Windows 11 gaming rig
# install both ollama and nssm
winget install ollama nssm
Now open your terminal as an administrator and run the remaining commands
Getting and sizing models
Mac 🖥️
If you are memory-constrained, meaning you're on an M series machine with 8 or 16 GB of shared memory, then stick to the 3b, 7b, and 13b sized models. If you're on an M2-M4 Mac with 24-64 GB of shared memory, then you can jump up to the higher quality models, like 27b, 30b, and even 70b, like llama3.3 which is comparable to the latest cloud versions of ChatGPT, Claude, and Gemini. From my testing on my M4 Pro, the inference speed and quality sweet spot are 14b to 27b models, like Gemma2 and phi4. I can run llama3.3:70b, thanks to my 64 gigs of RAM, but it's slow. Nonetheless, it's very impressive for a computer that looks like my Apple TV.... I just plan for a coffee break while waiting for a response.
ollama pull phi4
ollama pull gemma2
ollama pull qwen2.5
ollama pull llama3.3
ollama pull deepseek-r1:70b
Windows RTX 🕹️
With Windows and a dedicated graphics card, you get the benefits of much higher GPU performance, but are much more memory-constrained. From my research, you can utilize 20, 30, and 40 series cards to run local models; the later the series and the higher in that series you are, the better your results. Older cards, like a 2080 super, are going to be in the 7b range, maybe 13b depending on Vram and model quantization. Similar with the 30 series but with better overall performance. In general, the offload limit seems to be 30-34b models with a high-end card like a 3090 or a 4090 with 24 gigs of Vram. I'm testing with a 4090 with 24 gigs Vram, which performs incredibly well on models like Gemma2:27b, deepseek-r1:32b, qwen2.5:32b, and many others. Performance and responsiveness are comparable to the fastest cloud models, which is quite impressive. If I go up in model size, however, performance drops off a cliff, as work shifts to the CPU.
ollama pull gemma2:27b
ollama pull deepseek-r1:32b
ollama pull qwen2.5:32b
ollama pull codellama:34b
Deploy Open WebUI
OK, Ollama is up and running as a service on one or more machines, and now it's time to start working with those models you downloaded. My preferred tool for doing this is Open WebUI. I came across the project recently and have been loving it. It's under active development right now, so you and I should expect many changes to come, but I love that it is open source and is something I can contribute to. It has all of the features you would expect in ChatGPT, Claude, or Gemini, but unlike those tools, Open WebUI allows you to aggregate local and cloud models into the same environment and context. This allows you to choose the best AI for the task at hand. Not only that but all your chats, even when using Cloud AI models, are stored locally. I'm way underselling this, so please check out their Github and the docs site ...and keep reading to see it in action!
Docker
Docker is the best way to get started quickly and is well-documented on their site, but we'll be using the Advanced configuration, which allows us to use Ollama on another computer. You can, of course, run Docker on the same computer you installed Ollama, which is how I started, and a great way to make sure everything is working and performing well.
# if my ollama service is running on 10.1.1.75
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=http://10.1.1.75 \
-v open-webui:/app/backend/data --name open-webui \
--restart always ghcr.io/open-webui/open-webui:main
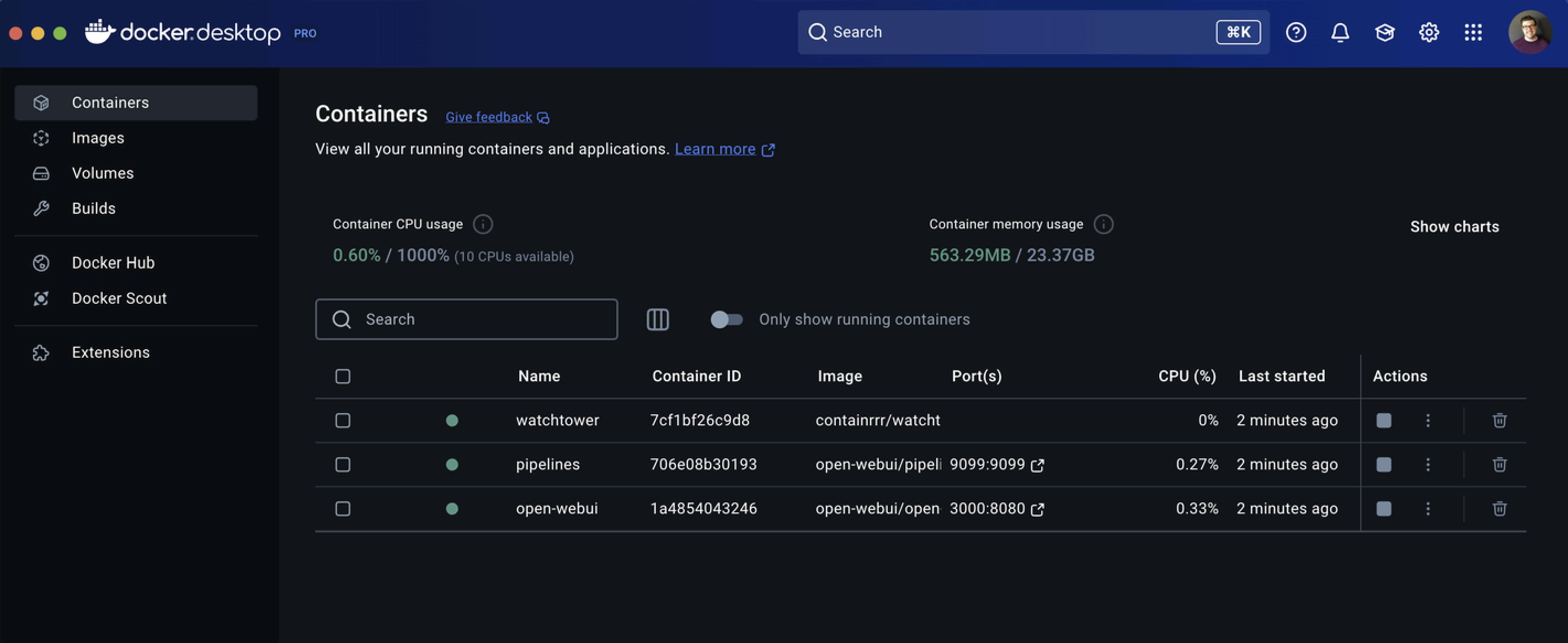
You can also run a Pipelines container (optional), which allows for building customizable workflows, like filters and functions. You may not leverage it now, but it's so easy to set up, so go for it. Open Web UI will automatically recognize it on startup.
docker run -d -p 9099:9099 --add-host=host.docker.internal:host-gateway \
-v pipelines:/app/pipelines --name pipelines \
--restart always ghcr.io/open-webui/pipelines:main
And finally, to keep everything updated.
docker run -d --name watchtower \
--volume /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower -i 300 open-webui

Kubernetes
I shifted most of my homelab apps over to Kubernetes quite a while ago now, and my services run with reasonable high-availability, shared persistent volumes, and TLS termination, so this is where I put my most critical apps. We'll have the same base functionality of the Docker setup, with quite a bit more. Open WebUI has a helm chart to get you started with some default configuration, but you can easily tweak it to your liking by passing your own custom values file.
If you're interested in setting up your own cluster, check out this post, which walks through a basic K3s setup, and then meet back here.

I'm doing a few things with my custom values that are not enabled with the default chart.
- I'm enabling pipelines, which will automatically install the pipelines chart as part of this release.
- I'm enabling persistent storage using my NFS provisioner. It is important to note that because Open WebUI uses SQLite as the primary database, it doesn't play nice with some PV provisioners. NFS on my NAS was my first choice, but I also use SMB and Longhorn. When I tested those, it created locking issues with the database. You can use an external Postgres database, but migrations are not yet supported with external databases, which may change. Stick to local storage (default), a manual persistent volume, NFS, or another provider you think may work.
- I'm enabling WebSockets and Redis for caching.
- Finally, I'm setting up ingress with TLS and nginx as my reverse proxy to ensure I have secure local access through Cloudflare Warp. Open WebUI was tricky to configure behind the proxy, though I managed to get it working through some trial and error.
Optional: To create your own free certificate via Let's Encrypt, check out my other post Migrating from Pi-hole to AdGuard home and scroll down to configuration and deployment.
kubectl create secret tls owui-tls-cert --namespace=openwebui \
--cert=fullchain.pem --key=privkey.pem
helm repo add open-webui https://helm.openwebui.com/
helm repo update
helm upgrade --install open-webui open-webui/open-webui \
--namespace openwebui --create-namespace \
--values openwebui-values.yaml

Configuration
Now that you are fully deployed, the configuration should be pretty straightforward. You've already specified your local Ollama endpoints in your Docker or Helm configuration, so those models should be connected and available after you create your admin account on your first login.
External API's
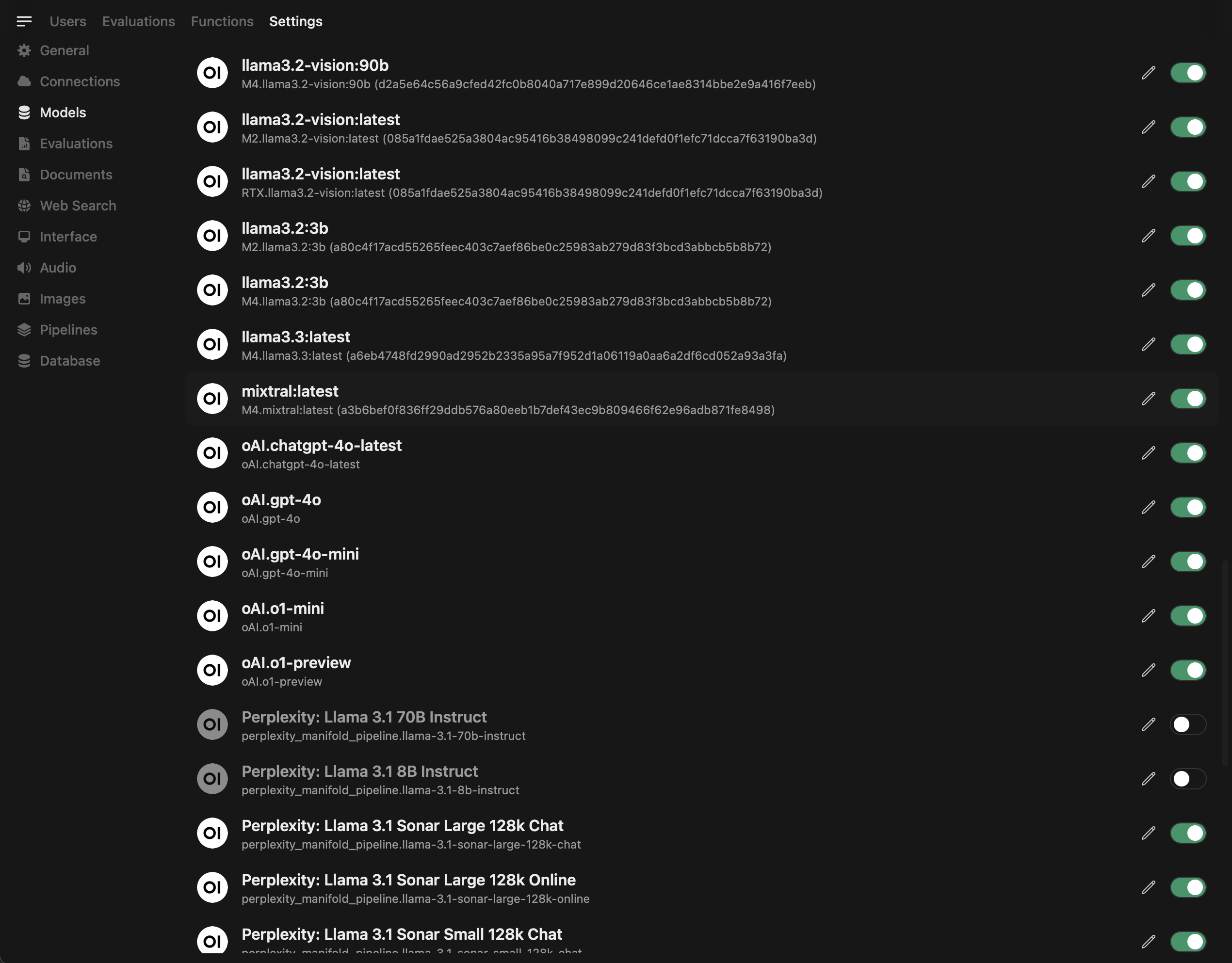
For OpenAI, you can add your API key and the default API URL (if not already there) directly on the connections page. This will pull all models available by default unless you are using a project key on the OpenAI side, which restricts the models available to use.
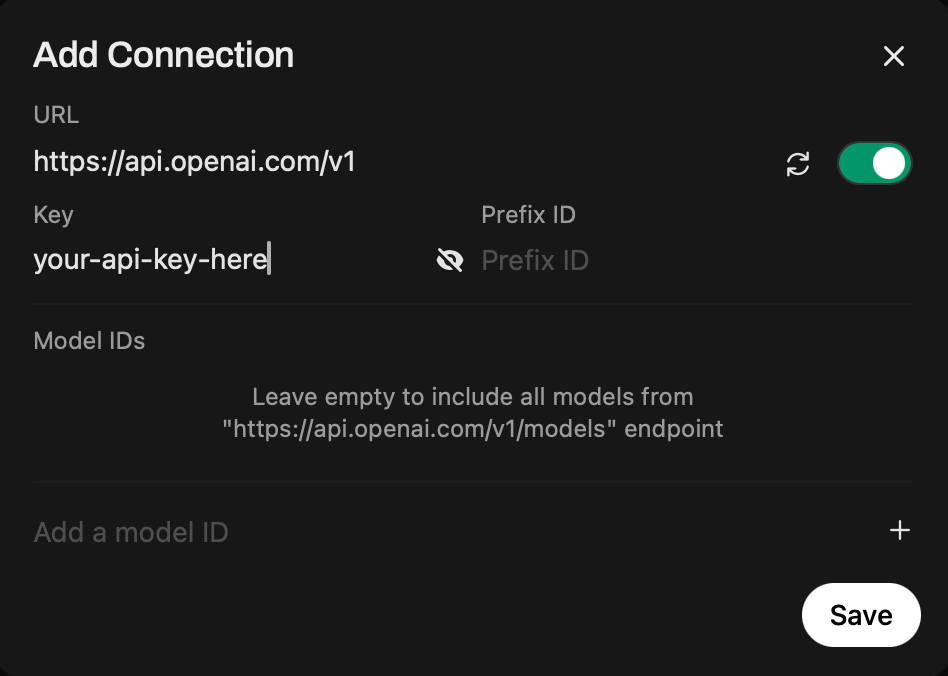
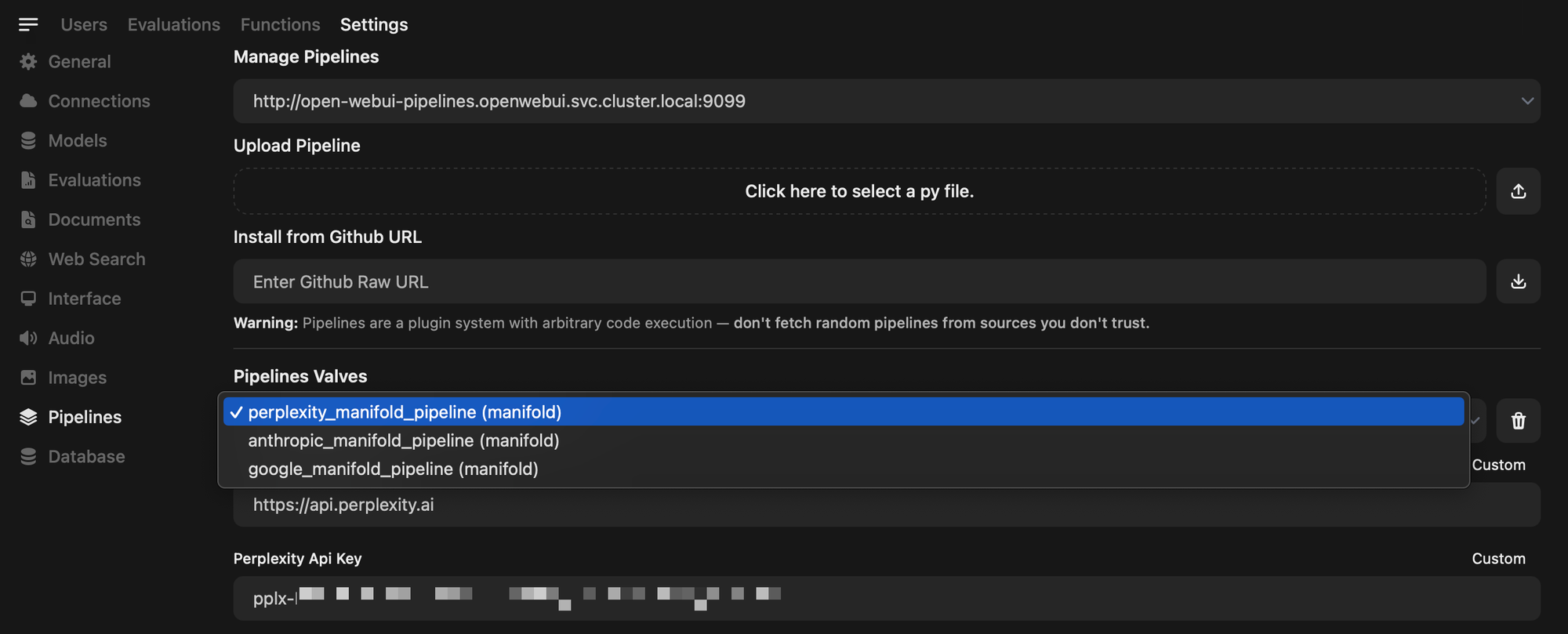
For Gemini, Claude, Perplexity, Hugging Face, and others. You'll need to use Functions or Pipelines. Essentially, Python code runs and integrates with the respective API's. There are already community functions available to get you up and running quickly, just add your key. There are also pipeline providers, which offer very similar functionality. You'll need API credits, and usage will vary by model, but it is generally very affordable for normal chats. Add $5 and have fun.
Web Search
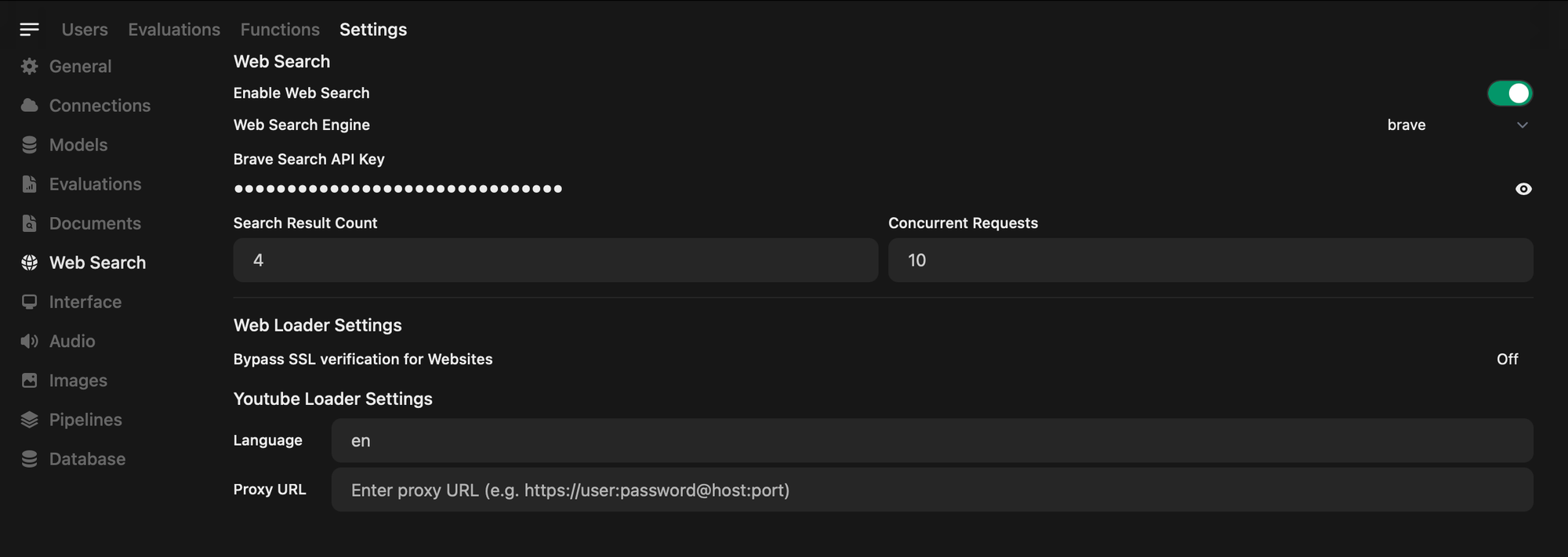
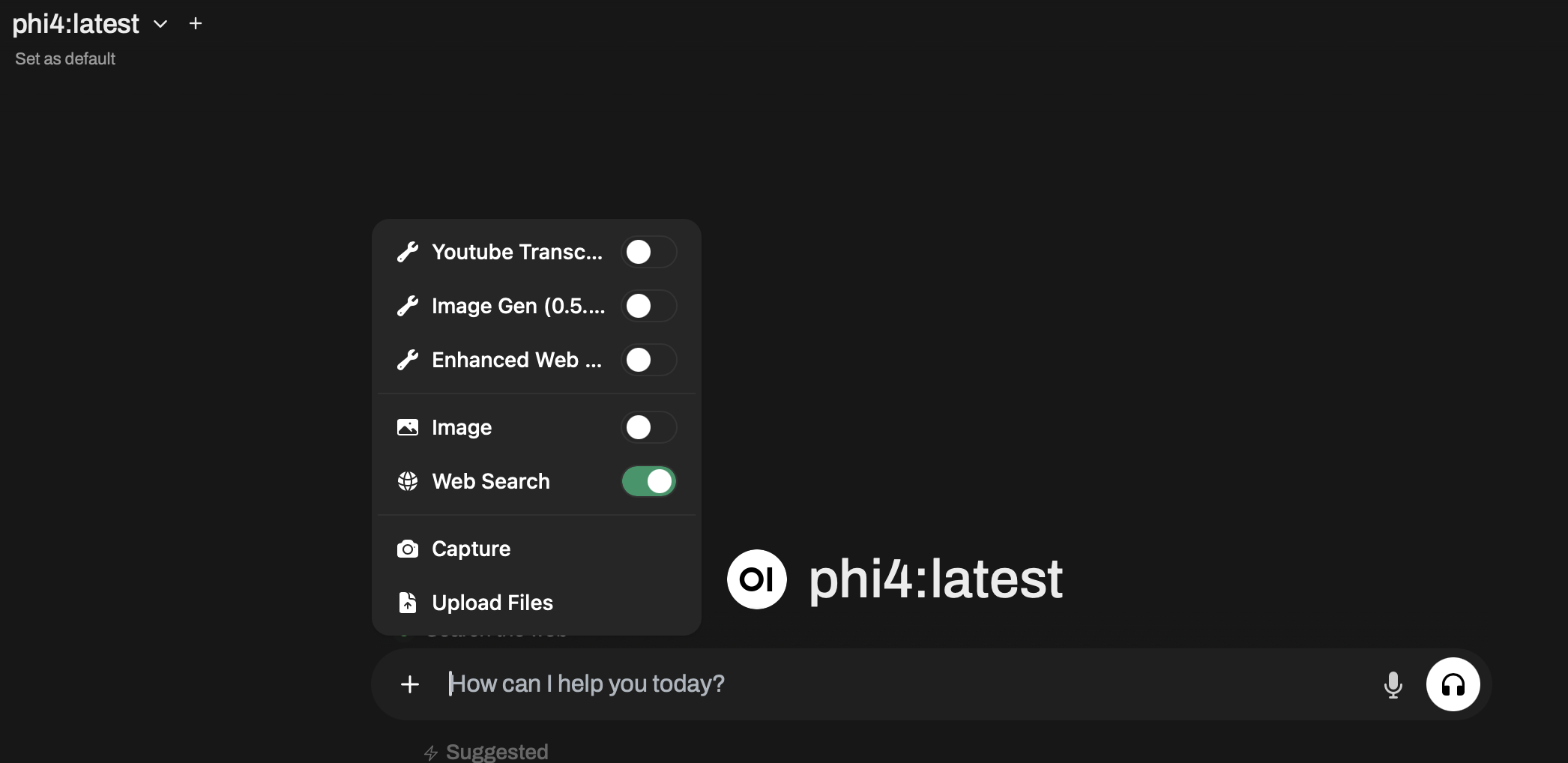
You can enable this same functionality with Open WebUI, a feature you may be used to in ChatGPT and something Perplexity does out of the box. Navigate to Admin Panel -> Settings -> Web Search and then choose your search provider and get their respective API key. I chose Brave search on their Free tier, which is perfect for my needs.
Chat Flex 💪
Now, let us have some fun with a little 1v1 chat-off.
| Metal | Specs |
|---|---|
| Mac Mini M2 Pro SOC | 32GB Shared Memory |
| Mac Mini M4 Pro SOC | 64GB Shared Memory |
| AMD 9800X3d CPU, NVIDIA RTX 4090 GPU | 64GB System Mem, 24GB Video Mem |
Side by side Phi4:14b (M2 Pro) vs Gemma2:27b (M4 Pro)
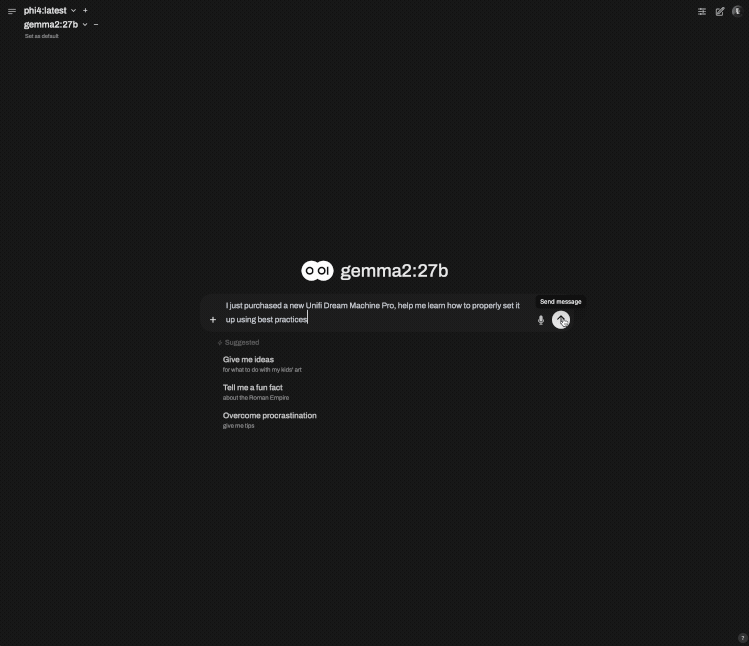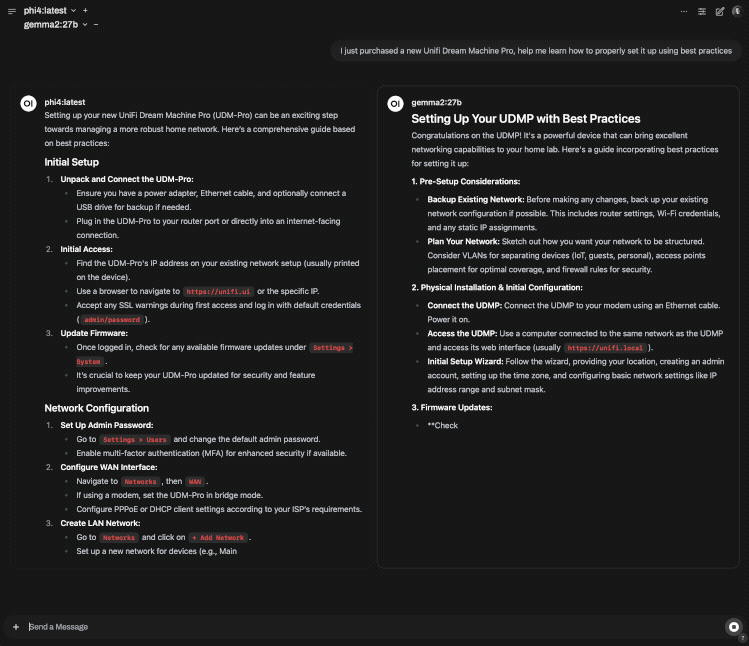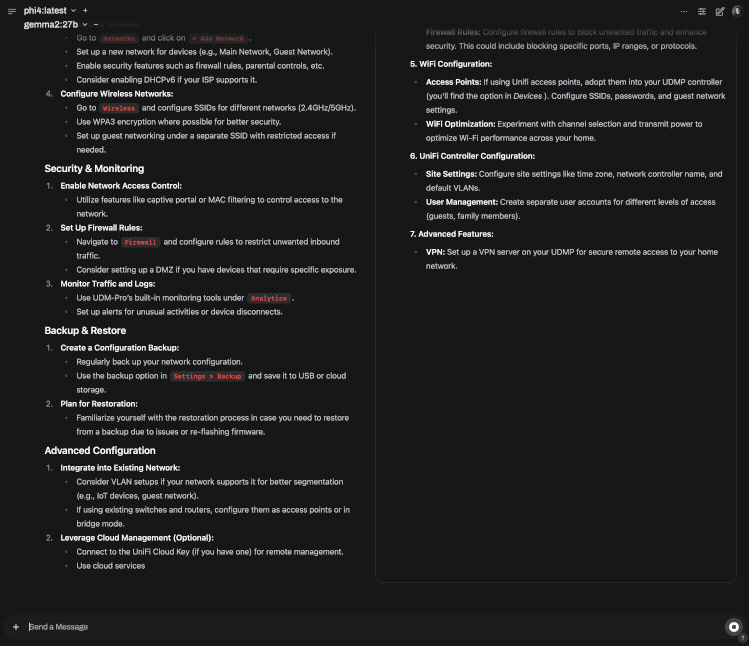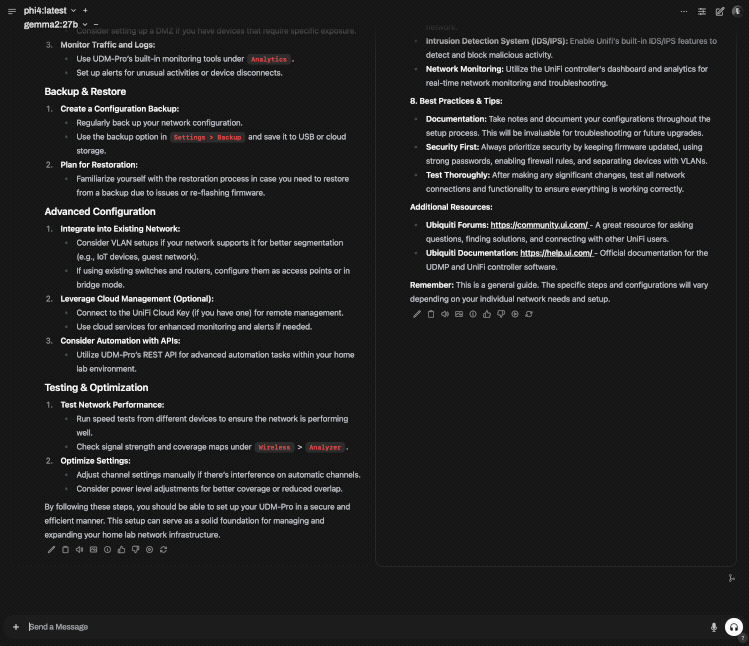
Gemm2:27b is a significantly larger model and performs very well on the M4 Pro, but gotta love the speed of Phi4 on the M2 Pro, and the quality isn't bad either.
Side by side Gemma2:27b M4 Pro vs Gemma2:27b RTX 4090
That RTX 4090 crushes the M4 Pro, taking less than half the time. If only it weren't so memory-constrained...perhaps a 5090 is in my future 🏦
Side by side Claude 3.5 Sonnet vs ChatGPT 4o latest
Speed: Both were very fast, as expected. Content: I give it to Claude.
I want my $20!
If you've made it this far, you might wonder, do I still need my subscriptions? Honestly, not really. After all, you're building a Home Lab, so what fun would it be to take the easy way? This is, of course, not completely free, as my M4 Pro fully loaded was quite expensive, as was my 4090 gaming rig, but I was going to buy those things anyway for my normal work and casual gaming. In fact, I was running those side-by-side queries while using the computers, so it's not disruptive to normal usage. The APIs are also not free, but the cost structures are very reasonable (or included with your sub) if you use the right model for the job. For example, not using use o1 when mini will do, or haiku instead of sonnet or opus will matter more when using the API. Bigger models for bigger tasks and smaller ones for smaller tasks are generally a good rule of thumb. The same goes for the open-source models. If you have the compute and sometimes the patience, skip the API's altogether. There are also product features to consider, like Projects, Web Search, local app integration, and Agents. Open WebUI and open-source projects have tackled many of those, but seeing how those products evolve will be interesting and perhaps worth the subscription fee. Either way, I like keeping my chats saved locally and I like that this is all in-house, I'm sure you will too. Have fun, and let me know how it goes.



